Writing GPU Drivers
About this article
I've realized that in most of my blog posts I kind of forget to describe what a given post is about. This post is for OSDevers, looking to write a GPU driver and not being sure where to begin. Should also be helpful for those wanting to get into Linux graphics dev.
Prerequisites
You should be very familiar with C (the language, C compilers & linkers, the preprocessor), a graphics API (preferably Vulkan), CPU assembly + SIMD extensions (AVX), basics of writing hardware drivers (what a PCIe BAR is, what is MMIO or an IRQ, what DMA means...), knowledge of Linux internals (you will be doing lots of reading Linux source code)
Git Repos
Mesa lives at https://gitlab.freedesktop.org/mesa/mesa
Vulkan-Loader lives at https://github.com/KhronosGroup/Vulkan-Loader
The basic process
Mostly, you will have to read and understand what Linux is doing, and reimplement it. Lots of staring at source code, dynamic debugging with a debugger + editing the src to add prints and dumping command buffers, disassemblies of shader machine code, etc.
The general architecture of Linux Graphics
The path of a Vulkan call goes the Vulkan Loader -> UMD (User Mode Driver) -> KMD (Kernel Mode Driver). The UMD is Mesa, the kmds live in the kernel tree. Both the UMD and KMD are called drivers, and you gotta tell from context which one is meant. "Vulkan driver" refers to the UMD, whereas "device driver" will usually refer to the KMD.
So, with Vulkan, first, vulkan-loader by Khronos provides the libvulkan.so library, and implements ICDs and whatnot. vulkan-loader has an ABI that Vulkan drivers have to comply with, implemented by Mesa's common Vulkan driver framework. Most of the vulkan common code lives in src/vulkan, with the individual drivers living in a vendor subdir, such as src/intel/vulkan for anv, src/intel/vulkan_hasvk for hasvk (essentially a divergent copy of anv before support for pre-gen9 GPUs was dropped, so the filenames are a bit confusing).
A Vulkan call, such as vkCreateInstance, will go thru vulkan-loader, which will resolve which driver to send it to.
Specifically vkCreateInstance will send it to multiple drivers, it's a bit complicated since in most setups, there's usually multiple drivers, and each might have multiple devices. A VkPhysicalDevice/VkDevice have a driver associated with it internally so that gets dispatched properly thru the trampoline, though you are "supposed" to use vkGetDeviceProcAddr to get the correct function pointer that will directly get dispatched to the correct driver, and in fact the trampoline in vulkan-loader does not implement some extensions, for those you will have to use the respective ProcAddr. It's called a "trampoline" because all it does is look into its dispatch tables and proxy the call to the correct driver.
If you list the symbols (readelf -s --wide) on libvulkan.so, you will see
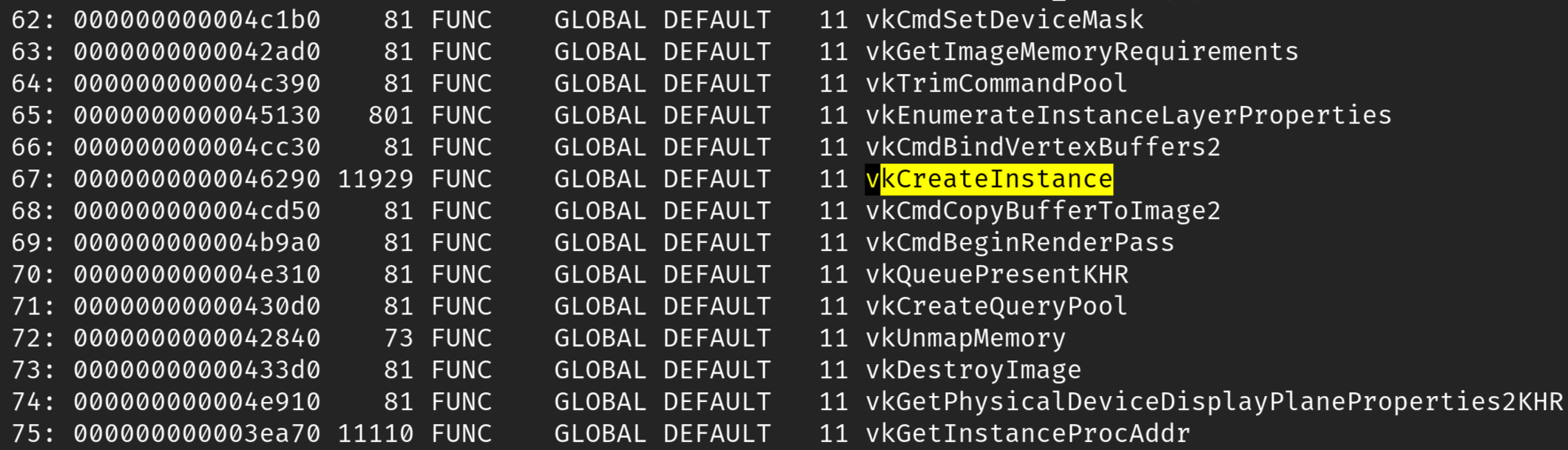
That they have functions present there. So, for example vkCreateInstance is defined in loader/trampoline.c. Additionally, there's lots of docs for the ABI that explains how these functions behave (docs/ subdir)
The loader will read the ICD config files (the paths can be overriden with env vars, etc), to find which drivers are available, and try to initialize them using the driver ABI. Eg. if we take the ICD file for anv (on my system it lives at /usr/share/vulkan/icd.d/intel_icd.x86_64.json
{
"ICD": {
"api_version": "1.4.318",
"library_arch": "64",
"library_path": "/usr/lib/libvulkan_intel.so"
},
"file_format_version": "1.0.1"
}
This specifies information about the driver, including a path to the .so file that is the actual driver. This manifest is also documented (see LoaderDriverInterface.md#driver-manifest-file-format)
Now, the actual symbols for the driver are not present in the symbol table (as they are communicated using the vulkan-loader ABI), but the debug info includes them, so something as simple as launching the test app with GDB works fine. Usually, the driver functions will just be a driver-specific prefix (such as anv_ for anv), then the function name, so, anv_AllocateMemory for eg.
More information about how this stuff works is available at this blog post: https://www.collabora.com/news-and-blog/blog/2022/03/23/how-to-write-vulkan-driver-in-2022/
Now, the Vulkan driver will create device-specific command streams, compile shaders into device-specific machine code, and dispatch jobs to the kernel with kmd-specific ioctls.
The kernel includes a generic interface for managing GPU buffers called "GEM" (Graphics Execution Manager). The drivers implement driver-specific ioctls for most things for operating with a GEM, such as allocating it (I915_GEM_CREATE_EXT on i915), mapping it (I915_GEM_MMAP_OFFSET on i915). These GEMs, which are scoped to a process as incremental IDs, can be converted to and fro a dmabuf with two ioctls (DRM_IOCTL_PRIME_FD_TO_HANDLE, DRM_IOCTL_PRIME_HANDLE_TO_FD). Most of this is somewhat described in the kernel's source comments, some high-level stuff is in Documentation/ as .rst files which are rendered online as kernel docs.
The kmd is responsible for initializing the hardware, if there's a display controller component, binding it to Kernel Mode Settings (KMS), taking care of memory management, and of actually dispatching jobs by talking to the device. Most modern GPUs have a hardware scheduler (GuC on Intel).
The actual graphics device communicates with the KMD thru MMIO exposed as a PCIe BAR + IRQs for certain events (on x86 - on other platforms, there's DT entries, plus usually the display controller and GPU are separate devices from separate vendors, oftentimes the DC is off-die from the SoC...)
Usually, the VRAM will be exposed a PCIe BAR (this is why ReBAR and whatnot is useful, it's how they get around the PCIe BAR size limit).
For example, my DG2 (Alchemist) Arc A770:
Memory at 81000000 (64-bit, non-prefetchable) [size=16M]
Memory at 6000000000 (64-bit, prefetchable) [size=16G]
First BAR are the registers, second BAR is the VRAM.
What a UMD has to do
So, a UMD will be implementing some graphics API, so it has to be able to get calls from this API (above I explained a bit of how it usually works for Vulkan, tho there's nothing saying you can't just make your own graphics API or write your own loader). It has to be able to speak to the KMD. First, figure out how to allocate memory on the GPU, and write to it (the above mentioned i915 ioctls are how you do this on i915 on Linux). Figure out how to query features of the device being driven by the KMD, because one KMD can drive a wide variety of devices with varying features. Then, figure out what format the GPU's command stream has, and correctly translate command buffers into this format. Intel's command stream is documented with public PRMs, plus the Mesa drivers allow dumping of the command stream, and implement the emitting of the commands with a bunch of macros.
Next, figure out how to compile your API's shading language into the GPU-specific machine code. Mesa once again allows dumping disassemblies of the various stages of the compilation process, which is very useful for this. You can use the Vulkan CTS to get lots of small test programs to dump and attach to with GDB. There's also a framework by Google, called Amber, that simplifies writing test programs.
What a KMD has to do
It has to initialize the device, and implement buffer management, job submission (so, talking to the hardware scheduler), etc. Generally, a KMD has a more "cliff-shaped" development. It has to do a lot before you are able to test it, compared to a UMD which can be developed more incrementally.
A bit about Intel GEN12
So, Intel GPUs (Talking about GEN12 here, I don't really know others) has several "engines" that are responsible for different things. There's a Render Engine, responsible for the GPU things, a Display Engine, responsible for display controller things, Media Engine, responsible for media things, and Copy Engine, responsible for various memory operations.
The Render Engine is the most relevant for a GPU driver, with the Display Engine being relevant for display stuff. Both have registers memory mapped at BAR0, documented in an Intel PRM. Each engine has its own PRM volume.
Each engine has a power well that controls if it's enabled or not. Intel GPUs use a hardware scheduler called "GuC" that runs signed firmware which has to uploaded on setup to be used. You can do software scheduling, but nobody tests it and very little is known about how to do it (if at all).
So, you have to figure out how to init the engines you wanna use by poking the registers (the offsets of each register as well as their format and meaning are documented thankfully, though the docs are pretty poor). The Render Engine has several "Command Streamers", which accept pointers to buffers containing command streams. There's RCS, which is the general command streamer (Render Command Streamer), also a CCS (Compute Command Streamer) which only accepts compute jobs.
The Render Engine implements both "3D" commands (rendering), and "GPGPU" commands (compute). Differentiating between both of those is done thru commands - 3DSTATE_ commands for setting up 3D things, for example (which are disallowed in CCS).
There's a bunch of commands needed to prepare info about the job being submitted, to configure the state, to load the shaders, configure the memory mappings to the shaders...
The shader itself is once again just a pointer to GPU memory. The GEN12 ISA is effectively SIMD with widths up to 32, a general register file that's 128 * 16 "words" long + a few special registers, an explicit way of synchronizing instructions (because there's integer and float instructions, which are executed in parallel), and a special feature in the hardware for accessing the GRF in weird ways, called "register regions" (see https://www.intel.com/content/www/us/en/developer/articles/technical/introduction-to-gen-assembly.html)